
Mapping (Medieval) Manuscript Migrations
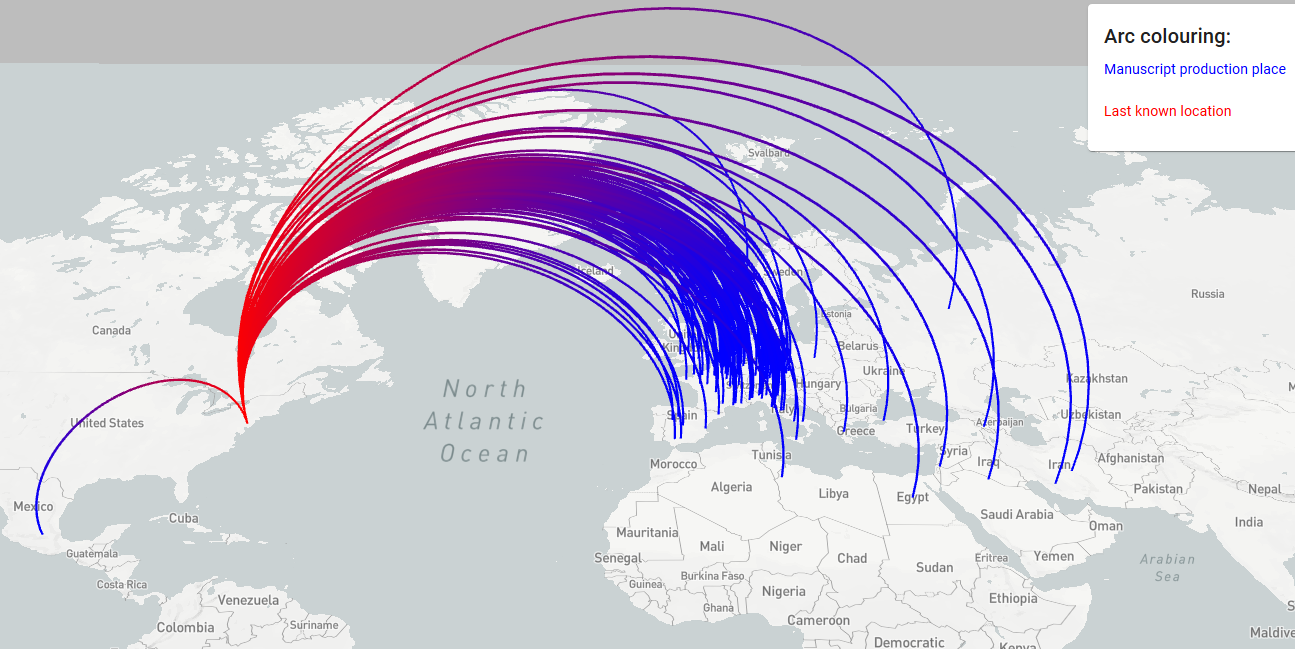
The end of this month will mark the culmination of Mapping Manuscript Migrations (MMM), a three-year-long project to create a linked data resource to research and track the historical movement of medieval manuscripts.
MMM — an awardee of the Trans-Atlantic Platform’s Digging into Data Challenge — is a collaboration between Penn Libraries’ Schoenberg Institute for Manuscript Studies, the e-Research Centre at the University of Oxford, the Institut de recherche et d’histoire des textes (IRHT) in Paris, and the Semantic Computing Research Group at Aalto University in Helsinki.
“The purpose of the collaboration was to bring together different data resources for the study of medieval manuscripts in a linked data environment, so that users can search across them,” says Lynn Ransom, the principal investigator for the project’s American team. “The presumed users are researchers — historians, art historians, collectors, and people working in the trade of rare books and manuscripts — who are interested in the history of manuscript production and collecting from medieval times to the present.”
The collaboration was engineered by Toby Burrows, the project director and principal investigator at the e-Research Center at Oxford. Burrows has especial scholarly interest in tracking manuscripts: one of his other endeavors is the reconstruction of Sir Thomas Phillipps’ manuscript collection. Over the course of his life, Phillipps acquired an estimated 60,000 European manuscripts — the largest such personal collection in history — which were then dispersed in sales before and after his death.
In his efforts to track the provenance and history of Phillipps’ many, many manuscripts, Burrows recognized the utility of a linked data environment containing centuries’ worth of information from several institutions.
MMM combined the expertise and resources of the historians on the team and the information scientists at Aalto University, who offered semantic computing expertise. Penn, Oxford, and IRHT contributed three different datasets and scholarly expertise. “Each set was constructed according to a distinct data modelling process and serves a different purpose,” explains Ransom. “So the problem was getting these three disparate datasets to talk to each other.”
The datasets came from Penn Libraries’ Schoenberg Database of Manuscripts, which contains more than 240,000 records of manuscripts observed in auction, sale, and institutional catalogs; the IRHT’s Bibale, which totals nearly 13,000 manuscript records; and the online catalogue Medieval Manuscripts in Oxford Libraries, a collection of more than 10,000 XML documents describing the University’s manuscripts.
The team imported the three sets into the MMM platform, converted the data into a unified Resource Description Framework (RDF) model, then linked it all using naming standards such as the Virtual International Authority File and GeoNames.
The original goal was to create a complete online research portal that would allow for the cross-searching of datasets from around the globe. However, challenges related to the transformation of the datasets into RDF forced the team to limit their efforts to the three original datasets, and the goal of the project pivoted to what Ransom now describes as a successful “proof of concept.”
The resulting MMM portal will thus provide the next project — or the continuation of this one — with a solid methodological foundation for developing a linked data interface for humanities research. The team presented their research results at the Round Four Digging into Data Challenge Conference in January earlier this year .
“Though there’s a lot of talk about linked data, the technology and languages you need to master for linked data aren’t widely known, especially among humanities scholars,” says Ransom. One unanticipated component of the MMM project was a weekly training program — led by members of the Aalto team and dubbed “Sparql Wednesdays” — in the RDF query language SPARQL (pronounced “sparkle”).
“Having to learn a computer language like SPARQL encourages humanists to think more scientifically about the way we handle and interpret data,” says Ransom. “If a researcher understands how data is structured, then they understand what they can and can’t do with it.”
For example, a researcher might want to know how many manuscripts were produced in London in the 15 th century. In order to glean the appropriate data, the query on the MMM website would have to be phrased something like, “Show all the manifestation singletons (a term used to describe manuscripts in the MMM dataset) associated with London between 1399 and 1501.” With these specific parameters, the application returns all of the data that meets these criteria.
Even though the result set may not be complete picture of all the manuscripts produced in London in the fifteenth century — a result, Ransom notes, that will likely never be fully realized — it returns enough data to provide the research with a statistically-sound notion of what manuscript production looked like in the fifteenth century.
Ransom identifies a divide between researchers inexperienced with the technology behind the tools they regularly use, and technologists who don’t often understand how the tools they’re developing will be used by researchers. MMM has outlined a path for breaching that divide.
“Learning how to use the technology can be an intimidating process for some researchers; it’s not like a book, where you just open it and flip the pages to get information,” says Ransom. “That’s a technology that we all take for granted. This is a new technology that allows us to look for information in different ways. But if researchers can overcome the fear of what’s behind the screen that they can’t see, the research becomes so much richer.”
Note: For Mapping Manuscript Migrations, each partner was funded by their respective national funding agency: The Institute of Museum and Library Services (Penn), the Economic and Social Research Council (Oxford), Agence nationale de la recherche (IRHT), and the Academy of Finland (Aalto).
Date
May 20, 2020