
Scraping Open Data from the Web with BeautifulSoup
Interested in retrieving data from the web? Learn how to scrape open data from websites with BeautifulSoup Python package along with the best practices.

During the first week of Research Data and Digital Scholarship Data Jam 2021 we discussed about “Sourcing the Data” by “Scraping Open Data from the Web”.
Here are the workshop materials including slides and Python code exercise.
Prerequisites
The “Web Scraping with BeautifulSoup” workshop presumes the attendees to have some knowledge of HTML/CSS and Python. The required software includes Jupyter Notebook, and Python packages like pip, sys, urllib.request, and bs4.
Web scraping or crawling is the process of fetching data from a third-party website by downloading and parsing the HTML code. Here we use the Python Requests library which enables us to download a web page. Then we use the Python BeautifulSoup library to extract and parse the relevant parts of the web page in HTML or XML format.
Farming the HTML Tags
The secret to scraping a webpage are the ingredients: These include the web page that is being scraped, the inspect developer tool, the tags and tag branch of the exact section of the web page being scraped, and finally, the Python script.
Structure of a Regular Web Page
Before we can do web scraping, we need to understand the structure of the web page we're working with and then extract parts of that structure.
<html>
<head>
<title>
</title>
</head>
<body>
<p>
</p>
</body>
</html>Python Demo
- Download the latest versions of Python and Anaconda3 depending on your system’s Operating System.
- Open the Anaconda Navigator and select Jupyter Notebook.
- Navigate to the directory where you want to hold your files. Create or upload a notebook, marked by .ipynb file extension.
-
Install the BeautifulSoup4 package bs4.
# Importing Python libraries import bs4 as BeautifulSoup import urllib.request
Scenario 1: I want to know more about storing fruits for the winter, using Wikipedia for collecting data.
For this workshop we will be using the Wikipedia web page on Fruit preserves.
- Inspect the webpage by right-clicking on the required data or pressing the F12 key
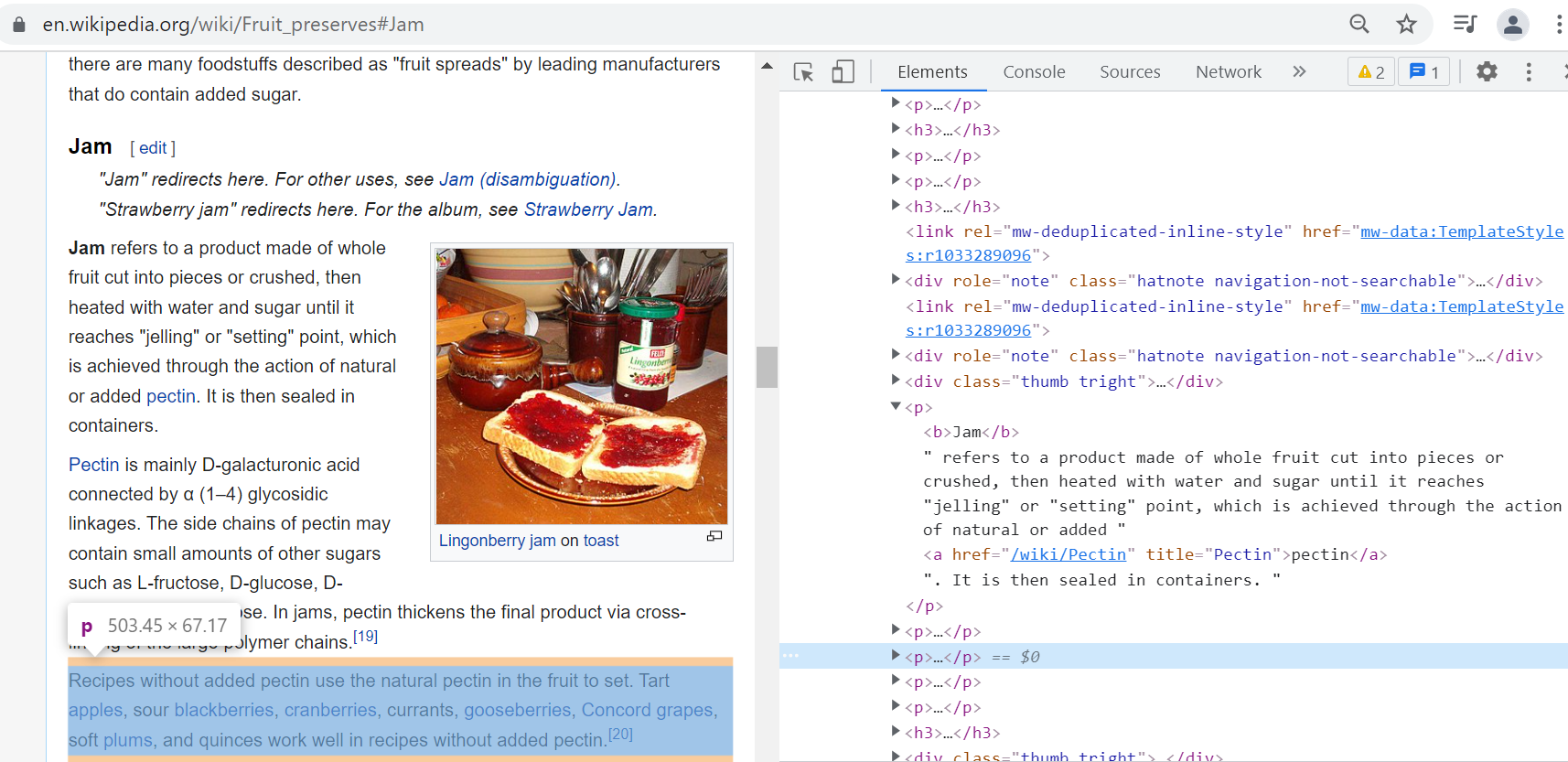
-
Get the link
# Fetching the content from the Wikipedia URL get_data = urllib.request.urlopen('https://en.wikipedia.org/wiki/Fruit_preserves') read_page = get_data.read() -
Parse the text data
# Parsing the Wikipedia URL content and storing the page text parse_page = BeautifulSoup.BeautifulSoup(read_page,'html.parser') # Returning all the <p> paragraph tags paragraphs = parse_page.find_all('p') page_content = '' -
Add text to string as is
# Looping through each of the paragraphs and adding them to the variable for p in paragraphs: page_content += p.text # Make the paragraph tags readable print(p.prettify()) -
Add text to string for paragraphs
for p in paragraphs: page_content += p.text print(p.get_text())
Scenario 2: I want to collect all European Paintings in the Philadelphia Museum of Art artworks collections with fruits in them.
- Understand the webpage data
- Go to the museum website https://philamuseum.org/
- Go to the online collection https://philamuseum.org/collections/search.html
- Select the European painting filter and search for the keyword "fruit"
- Inspect the webpage https://philamuseum.org/collections/results.html?searchTxt=fruit&searchNameID=&searchClassID=&searchOrigin=&searchDeptID=5&keySearch2=&page=1
- Identify the container tag. Here it is the class "pinch"
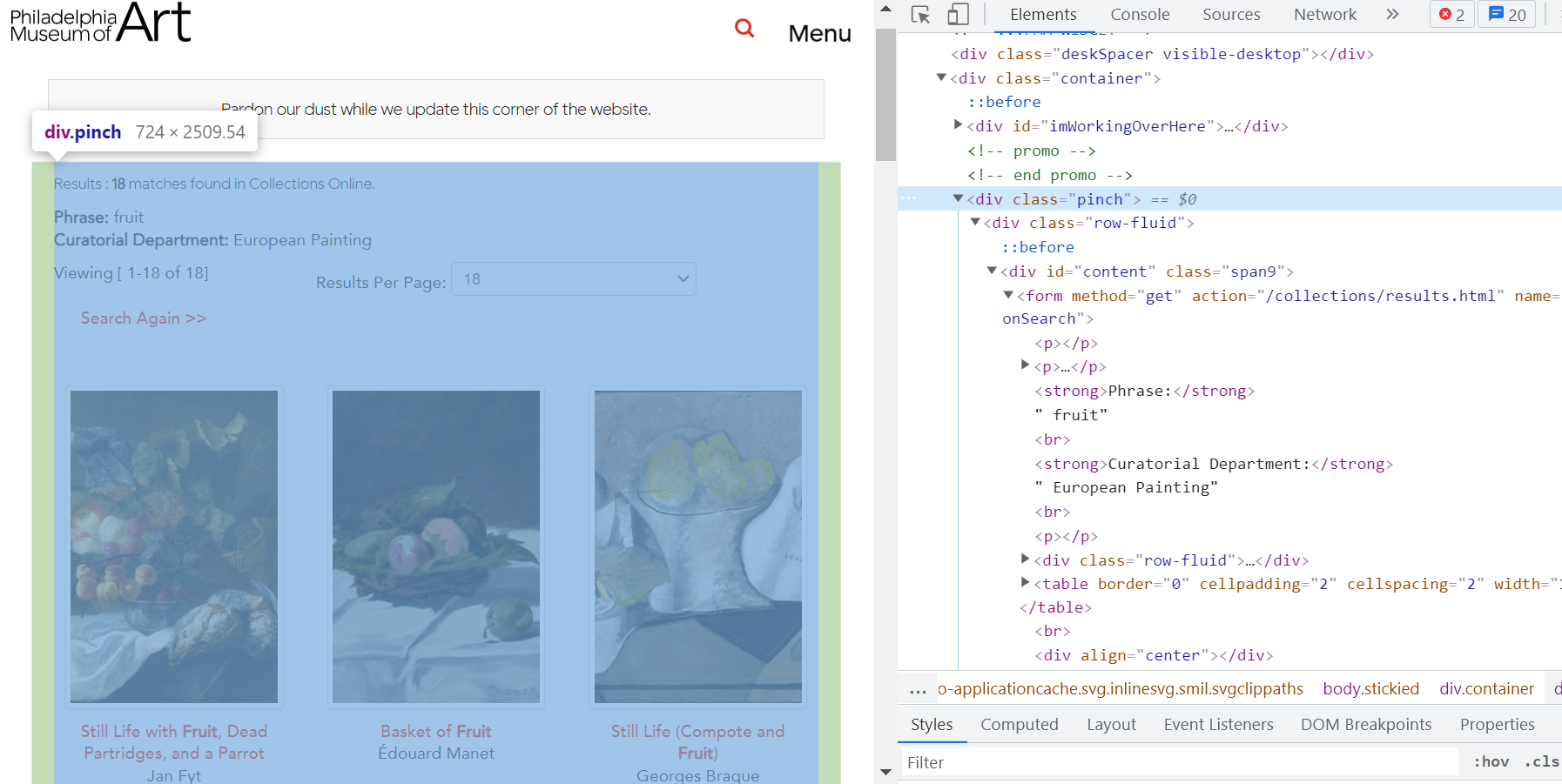
- Identify the link tag "a href"
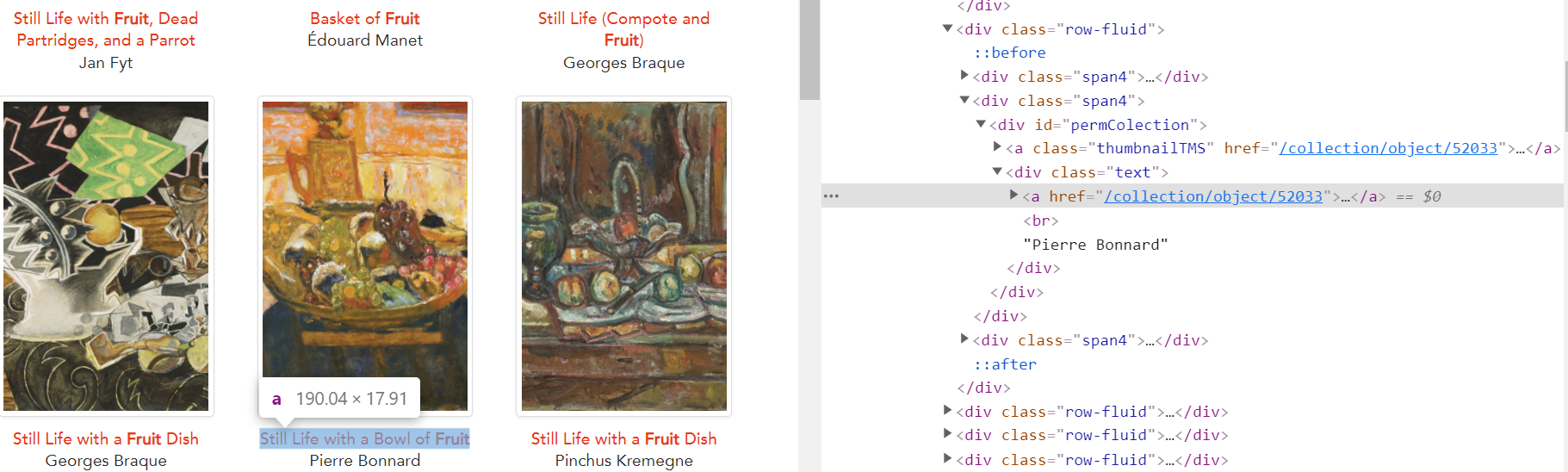
-
Import the libraries and fetch the webpage
import requests from bs4 import BeautifulSoup page = requests.get('https://philamuseum.org/collections/results.html?searchTxt=fruit&searchNameID=&searchClassID=&searchOrigin=&searchDeptID=5&keySearch2=&page=1') soup = BeautifulSoup(page.text, 'html.parser') -
Select the HTML tags
# Locating the HTML tags for the hyperlinks art = soup.find(class_='pinch') art_objects = art.find_all('a') for artwork in art_objects: links = artwork.get('href') print(links) -
Export to CSV (comma separated value) table
import csv import requests from bs4 import BeautifulSoup page = requests.get('https://philamuseum.org/collections/results.html?searchTxt=fruit&searchNameID=&searchClassID=&searchOrigin=&searchDeptID=5&keySearch2=&page=1') soup = BeautifulSoup(page.text, 'html.parser') art = soup.find(class_='pinch') art_objects = art.find_all('a') for artwork in art_objects: links = artwork.get('href') # Open a csv file to write the output in f = csv.writer(open('pma.csv', 'w')) for artwork in art_objects: links = 'https://philamuseum.org' + artwork.get('href') # Insert each iteration's output into the csv file f.writerow([links])
Why Scrape Data?
- Open Data Collection from obsolete or expired websites
- Open Data Access in the absence of an API (Application Programming Interface)
- Automated real-time data harvesting
- Data Aggregation
- Data Monitoring
Challenges
- For effective web scraping, script customizations, error handling, data cleaning, and results storage, are necessary steps and thus making the process time and resources intensive.
- Websites are Dynamic and always in development. The content of a website changing reflects in the tags that are selected in your script. This is especially important to consider in the case of real-time data scraping.
- Python packages and updates sometimes constitute in unstable scripts
- It is extremely important to throttle your request or cap it to a specific amount for server considerations to not overload the server usage.
Spoonfuls of Data Helps the Servers NOT Go Down
Here are resources on learning more about University of Pennsylvania Libraries Policy of server usage:
- Policy on Acceptable Use of Electronic Resources
- Use Policy for “Penn Only” Electronic Resources
- Accessing Electronic Resources (On and Off Campus / EZproxy)
Alternatives
- ScraPy – Framework for large scale web scraping
- Selenium – Browser Automation Library for Web Scraping using JavaScript
- rvest – R package for multi-page web scraping
- API (Application Programming Interface) – Direct data requests from the source
- DOM (Document Object Model) parsing
- Pattern matching text – Using regex (regular expressions) for selecting text
- Manually copy-pasting
Resources
- ProgrammingHistorian Intro to BeautifulSoup Tutorial
- BeautifulSoup Documentation
- DataQuest Interactive Tutorial – Contact Research Data and Digital Scholarship for license
- Mozilla Developer Network HTML Basics
- Mozilla Developer Network HTML elements reference